PythonとKerasによるディープラーニングを読み進める その2の続きです。
前回は二値分類の問題を解きましたが、今回は多クラス分類の問題解きました。
ニュース配信の分類
ニュース配信を46種類の相互排他なトピック(クラス)に分類するネットワークを構築する。
Reutersデータセット
IMDbの二値分類問題とモデルをほぼ変えずにある程度予想することができる。
モデル定義
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
x_val = x_train[:1000]
partical_x_train = x_train[1000:]
y_val = y_train[:1000]
partical_y_train = y_train[1000:]
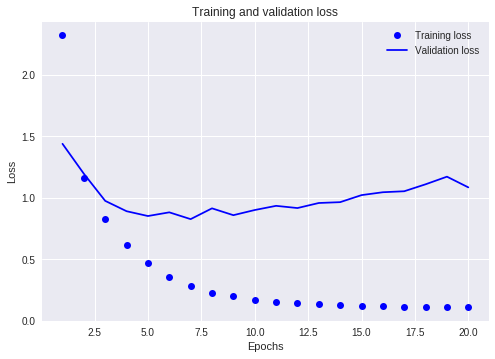
history = model.fit(partical_x_train, partical_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))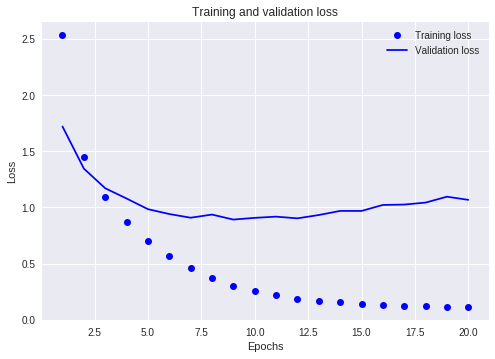
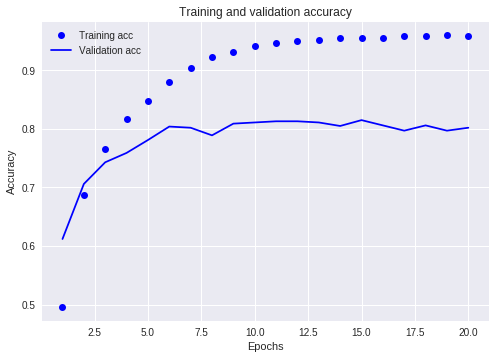
- 隠れユニット数
- 出力層の活性化関数
- 損失関数に多クラス交差エントロピーを指定していること
出力が46カテゴリなので、隠れユニット数はそれを下回らないように設定したほうが良い。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])例えば上記のモデルでは、ユニット数が4の中間層がボトルネックになり、損失率が上がる。
ちなみに私が試した限りでは、中間層のユニット数を128に上げてみたりしたが、損失率はあまり変化がなかった。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(128, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
x_val = x_train[:1000]
partical_x_train = x_train[1000:]
y_val = y_train[:1000]
partical_y_train = y_train[1000:]
history = model.fit(partical_x_train, partical_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))